Laden...
Finance Agent
Zahlungseingänge automatisch offenen Posten zuordnen – deterministisch zuerst, KI wo nötig, Klärfälle an Menschen.
Der Wert liegt nicht im 1:1-Treffer, sondern im Umgang mit der Realität
Saubere Zahlungen mit korrekter Referenz kann jedes System zuordnen. Der Finance Agent ist für den Rest gebaut: Teil- und Sammelzahlungen, Abzüge (Skonto, Spesen, Währungsdifferenzen), fehlende oder falsche Verwendungszwecke und Fälle, in denen der Zahler nicht der Rechnungsempfänger ist.
- Kontoauszüge & Avise importieren: CAMT.053, MT940, CSV/Excel und Zahlungsavise (z. B. Zahlungsdienstleister, Marktplätze)
- Offene-Posten-Listen anbinden: OP-Listen als CSV/Excel – ohne ERP-Projekt, Integration nach Bedarf
- Jede Zuordnung mit Konfidenz und Begründung – Differenzen werden explizit ausgewiesen, nie versteckt
- Lernt aus jeder Freigabe: Zahler-Zuordnungen, Referenzmuster und typische Abzüge steigern die Auto-Quote über Zeit
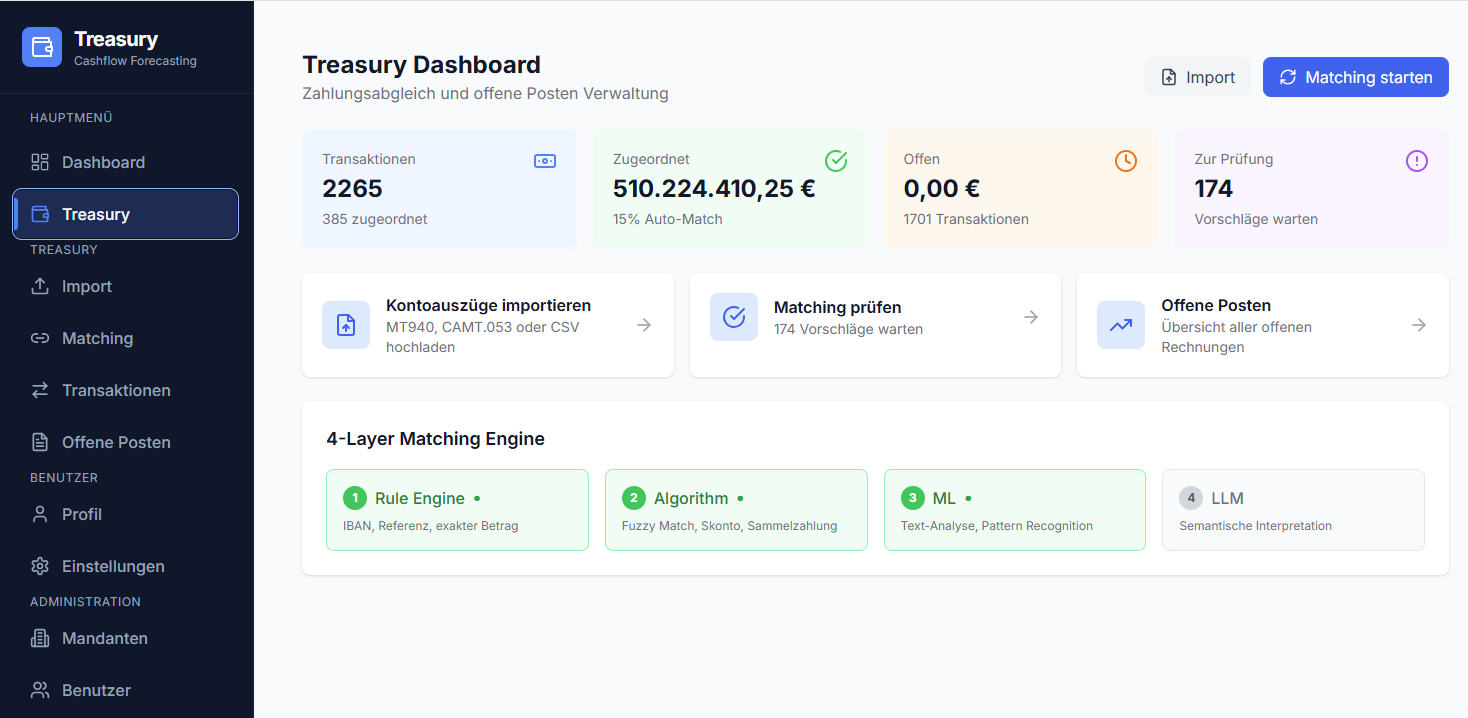
Intelligentes Matching
Zuordnung von Zahlungen zu offenen Posten – inkl. Teilzahlungen, Sammelzahlungen und Kombinationen mehrerer Rechnungen, jeweils mit Konfidenz.
Klärungs-Queue statt Blindbuchen
Nur Zuordnungen über der Konfidenz-Schwelle laufen automatisch. Alles andere geht mit Kandidaten und Begründung an Ihr Team – bestätigen, korrigieren, splitten.
Reale Eingangsformate
CAMT.053, MT940, CSV/Excel mit unterschiedlichen Spalten-Layouts, Zahlungsavise mit Gebühren-Abzügen – so, wie die Daten wirklich ankommen.
Lerneffekt pro Mandant
Jede Bestätigung und Korrektur wird gelernt: Zahler-Aliasse, Referenzmuster, typische Abzüge – die Automatisierungsquote wächst mit der Nutzung.
Deterministisch zuerst, KI wo nötig
Das Matching eskaliert stufenweise – transparent und nachvollziehbar:
- Stufe 1 – Regeln & Kombinatorik: Rechnungsnummern, Referenzen, exakte Beträge, Kombinationen offener Posten – deterministisch und schnell
- Stufe 2 – Semantik per LLM: nur für Fälle ohne verwertbare Referenz, z. B. freie Verwendungszwecke oder unbekannte Zahler
- Stufe 3 – Mensch: alles unterhalb der Konfidenz-Schwelle landet in der Klärungs-Queue, nichts wird still ausgeglichen
Wichtige Konsequenz: Geldbeträge werden nie vom Sprachmodell erzeugt – gerechnet wird ausschließlich deterministisch. Leitlinie ist „null falsche Ausgleiche vor hoher Auto-Quote“.
Erklärbarkeit statt Magie
Jeder Vorschlag kommt mit Begründung (welche Signale gepasst haben), Konfidenz und dem verbleibenden offenen Betrag – damit Fachbereiche sicher entscheiden können.
Review-Workflow
Standardfälle laufen automatisch, nur Klärfälle gehen in die Prüfung – mit Freigabe durch Ihr Team.
Audit Trail
Jede Entscheidung ist nachvollziehbar: wer, wann, warum – für Revision und Team-Transparenz.
Ausbaustufen
Der Zahlungsabgleich ist die erste Stufe. Darauf bauen – je nach Bedarf im Projekt – weitere Schritte auf. Diese Stufen sind Roadmap, kein fertiges Produkt:
E-Rechnung & weitere Formate
Strukturierte E-Rechnungen (ZUGFeRD/XRechnung), weitere Bank-Reports und PDF-OP-Listen als zusätzliche Eingangskanäle.
Abgleich in beide Richtungen
Vom Zahlungseingang zum Rechnungseingang: dieselbe Abgleich-Logik für die Kreditorenseite (Eingangsrechnungen, Bestellbezug).
Cashflow-Forecast
Wenn Zahlungen und offene Posten sauber zugeordnet sind, entsteht die Datenbasis für belastbare Liquiditätsprognosen – als späterer Schritt, nicht als Startpunkt.
Wofür Teams das einsetzen
- Debitorenbuchhaltung entlasten: Standardfälle automatisch, nur echte Klärfälle bleiben beim Team
- Abschluss beschleunigen: weniger manuelles Suchen und Zuordnen zum Monatsende
- Offene Posten im Griff: Differenzen, Teilzahlungen und Restbeträge strukturiert statt in Excel-Nebenlisten